
겉바속촉
[가이드라인] 2017 개인정보 비식별 조치 가이드라인-재식별 가능성 검토 기법 본문
개인정보 비식별 조치 방법
재식별 가능성 검토 기법(프라이버시 보호 모델)
| 기법 | 의미 | 적용례 |
| k-익명성 | • 특정인임을 추론할 수 있는지 여부를 검토, 일정 확률수준 이상 비식별 되도록 함 |
• 동일한 값을 가진 레코드를 k개 이상으로 함. 이 경우 특정 개인을 식별할 확률은 1/k임 |
| l-다양성 | • 특정인 추론이 안된다고 해도 민감한 정보의 다양성을 높여 추론 가능성을 낮추는 기법 |
• 각 레코드는 최소 l개 이상의 다양성을 가지도록 하여 동질성 또는 배경지식 등에 의한 추론 방지 |
| t-근접성 | • ℓ-다양성 뿐만 아니라, 민감한 정보의 분포를 낮추어 추론 가능성을 더욱 낮추는 기법 |
• 전체 데이터 집합의 정보 분포와 특정 정보의 분포 차이를 t이하로 하여 추론 방지 |
1. k-익명성(k-anonymity)
프라이버시 보호를 위한 기본 모델 공개된 데이터에 대한 연결공격(linkage attack) 등 취약점*을 방어하기 위해 제안된 프라이버시 보호 모델
| • 개인정보를 포함한 공개 데이터 - 일반적으로 활용하는 데이터에는 이름, 주민등록번호 등과 같이 개인을 직접 식별할 수 있는 데이터는 삭제 - 그러나 활용 정보의 일부가 다른 공개되어 있는 정보 등과 결합하여 개인을 식별하는 문제(연결공격)가 발생 가능 • 연결공격(linkage attack) - 예를 들어, <표 1>의 의료데이터가 <표 2>의 선거인명부와 지역 코드, 연령, 성별에 의해 결합되면, 개인의 민감한 정보인 병명이 드러날 수 있음 (ex) 김민준 (13053, 28, 남자)→ 환자 레코드 1번→ 전립선염 - 미국 매사추세츠 주, ‘선거인명부’와 ‘공개 의료데이터’가 결합하여 개인의 병명 노출 사례 |
(정의) 주어진 데이터 집합에서 같은 값이 적어도 k개 이상 존재하도록 하여 쉽게 다른 정보로 결합할 수 없도록 함 - 데이터 집합의 일부를 수정하여 모든 레코드가 자기 자신과 동일한(구별되지 않는) k-1개 이상의 레코드를 가짐 - 예를 들어, <표 1>의 의료 데이터가 비식별 조치된 <표 3>에서 1~4, 5~8, 9~12 레코드는 서로 구별되지 않음



--> 여기서, 같은 속성자 값들로 비식별된 레코드들의 모임을 ‘동일 속성자 값 집합 (equivalent class, 이하 동질 집합)’이라고 함
2. ℓ-다양성(ℓ-diversity)
k-익명성의 취약점*을 보완한 프라이버시 보호 모델 k-익명성에 대한 두 가지 공격, 즉 동질성 공격 및 배경지식에 의한 공격을 방어하기 위한 모델
(정의) 주어진 데이터 집합에서 함께 비식별되는 레코드들은 (동질 집합에서) 적어도 ℓ개의 서로 다른 민감한 정보를 가져야 함
- 비식별 조치 과정에서 충분히 다양한(ℓ개 이상) 서로 다른 민감한 정보를 갖도록 동질 집합을 구성
정보가 충분한 다양성을 가지므로 다양성의 부족으로 인한 공격에 방어가 가능하고, 배경지식으로 인한 공격에도 일정 수준의 방어능력
• 취약점 1. 동질성 공격 (Homogeneity attack)
- k-익명성에 의해 레코드들이 범주화 되었더라도 일부 정보들이 모두 같은 값을 가질 수 있기 때문에 데이터 집합에서 동일한 정보를 이용하여 공격 대상의 정보를 알아내는 공격
- <표 3>에서 범주화의 기초가 되는 정보(지역코드, 연령, 성별)에 대해서는 여러 다양한 값들이 혼재되어 있어서 연결 공격에 의한 식별이 어렵지만, 이 정보와 연결된 정보(질병)는 ‘k-익명성’의 기초가 아니 기 때문에 발생할 수 있는 현상
- 예를 들어, <표 3>에서 레코드 9~12의 질병정보는 모두 ‘위암’이므로 k-익명성 모델이 적용되었음에 도 불구하고 그 질병정보가 직접적으로 노출됨
• 취약점 2. 배경지식에 의한 공격 (Background knowledge attack)
- 주어진 데이터 이외의 공격자의 배경 지식을 통해 공격 대상의 민감한 정보를 알아내는 공격
- <표 2>와 <표 3>에서 공격자가 ‘이지민’의 질병을 알아내려고 하면 정보의 결합(13068, 29, 여)에 따라 ‘이지민’은 <표 3>의 1~4 레코드 중 하나이며 질병은 전립선염 또는 고혈압임을 알 수 있음
- 이 때, ‘여자는 전립선염에 걸릴 수 없다’라는 배경 지식에 의해 공격 대상 ‘이지민’의 질병은 고혈압으로 쉽게 추론 가능함
• k-익명성의 취약점의 원인
- 다양성의 부족 (lack of diversity)
•비식별 조치 할 때 정보의 다양성을 고려하지 않음
•동일한 정보를 가진 (다양하지 않은) 레코드가 비식별되어 하나의 ‘동질 집합’으로 구성될 경우 동질성 공격에 무방비 - 강한 배경지식 (strong background knowledge)
•k-익명성은 ‘여자는 전립선염에 걸리지 않는다’ 또는 ‘남자는 자궁암에 걸리지 않는다’와 같은 공격자의 배경지식을 고려하지 않아 이를 이용한 공격에 취약
예를 들어, <표 4>에서 모든 동질 집합은 3-다양성(ℓ=3)을 통해 비식별되어 3개 이상의 서로 다른 정보를 가짐
- <표 3>과 같이 동일한 질병으로만 구성된 동질 집합이 존재하지 않음
- 공격자가 질병에 대한 배경지식(예: 여자는 전립선염에 걸리지 않음)이 있더라도 어느 정도의 방어력을 가지게 됨\
(예: 여성 이지민이 속한 동질 집합 2, 3, 11, 12에서 전립선염을 제외하더라도 고혈압, 위암 중 어느 질병이 이지민의 것인지 여전히 알 수 없음)

3. t-근접성(t-closeness)
값의 의미를 고려하는 프라이버시 모델 ℓ-다양성의 취약점*(쏠림 공격, 유사성 공격)을 보완하기 위해 모델
• 쏠림 공격 (skewness attack)
- 정보가 특정한 값에 쏠려 있을 경우 ℓ-다양성 모델이 프라이버시를 보호하지 못함
<쏠림 공격의 예>
•임의의 ‘동질 집합’이 99개의 ‘위암 양성’ 레코드와 1개의 ‘위암 음성’ 레코드로 구성되어 있다 가정
•공격자는 공격 대상이 99%의 확률로 ‘위암 양성’이라는 것을 알 수 있음
• 유사성 공격 (similarity attack) - 비식별 조치된 레코드의 정보가 서로 비슷하다면 ℓ-다양성 모델을 통해 비식별 된다 할지라도 프라이버시가 노출될 수 있음
<유사성 공격의 예>
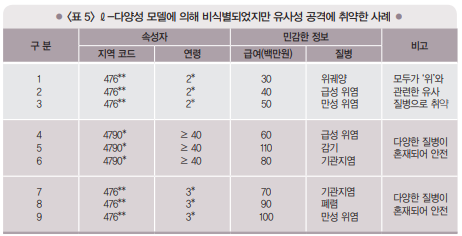
•<표 5>는 3-다양성(ℓ=3) 모델을 통해 비식별 된 데이터
•레코드 1,2,3이 속한 동질 집합의 병명이 서로 다르지만 의미가 서로 유사함(위궤양, 급성 위염, 만성 위염)
•공격자는 공격 대상의 질병이 ‘위’에 관련된 것이라는 사실을 알아낼 수 있음
•또 다른 민감한 정보인 급여에 대해서도 공격 대상이 다른 사람에 비해 상대적으로 낮은 급여 값을 가짐을 쉽게 알아낼 수 있음(30 ~ 50백만원)
(정의) 동질 집합에서 특정 정보의 분포와 전체 데이터 집합에서 정보의 분포가 t이하의 차이를 보여야 함
- 각 동질 집합에서 ‘특정 정보의 분포’가 전체 데이터집합의 분포와 비교하여 너무 특이하지 않도록 함
- <표 5>에서 전체적인 급여 값의 분포는 30 ~ 110이나 레코드 1, 2, 3이 속한 동질 집합에 서는 30 ~ 50으로 이는 전체 급여 값의 분포(30 ~ 110)와 비교할 때 상대적으로 유사한 수준이라 볼 수 있음 → 공격자는 근사적인 급여 값을 추론할 수 있음
- t-근접성 모델은 이러한 동질 집합과 전체 데이터 집합 사이의 분포의 과도한 차이를 ℓ-다양성 모델의 취약점으로 규정함
‘정보의 분포’를 조정하여 정보가 특정 값으로 쏠리거나 유사한 값들이 뭉치는 경우를 방지
- <표 6>에서 t-근접성 모델에 따라 레코드 1, 3, 8은 하나의 동질 집합
- 이 경우, 레코드 1, 3, 8의 급여의 분포는 (30 ~ 90)으로 전체적인 급여의 분포(30 ~ 110)와 큰 차이가 나지 않음
- 또한, 레코드 1, 3, 8의 질병 분포는 위궤양, 만성위염, 폐렴으로 병명이 서로 다르고 질병이 ‘위’와 관련된 것 이외에 ‘폐’와 관계된 것도 있어 특정 부위의 질병임을 유추하기 어려움
- 따라서 <표 5>의 경우와 비교하여 공격자가 공격 대상의 정보를 추론하기가 더욱 어려워짐

t수치가 0에 가까울수록 전체 데이터의 분포와 특정 데이터 구간의 분포 유사성이 강해지기 때문에 그 익명성의 방어가 더 강해지는 경향
- 익명성 강화를 위해 특정 데이터들을 재배치해도 전체 속성자들의 값 자체에는 변화가 없기 때문에 일반적인 경우에 정보 손실의 문제는 크지 않음
'IT 일기 (상반기) > 가명처리' 카테고리의 다른 글
| [가이드라인] 2017 개인정보 비식별 조치 가이드라인-개인 식별요소 삭제 방법 (0) | 2021.11.15 |
|---|---|
| [가이드라인] 2017 개인정보 비식별 조치 가이드라인 (0) | 2021.11.15 |
| [ARX] ARX privacy model - Privacy model (0) | 2021.11.15 |
| [ARX] ARX 이해하기 - Risk analysis perspective (0) | 2021.11.12 |
| [ARX] ARX 이해하기 - Utility analysis (0) | 2021.11.12 |

