
겉바속촉
[ARX] ARX 이해하기 - Utility analysis 본문
ARX에 대한 이해가 더 필요한 것 같아서 더 알아보겠습니다. ಥ_ಥ
참고 사이트 : https://arx.deidentifier.org/anonymization-tool/#a22
3. Utility analysis perspective
유틸리티 분석 관점은 예상되는 사용 시나리오에 대한 특정 변환의 적합성을 평가하는 데 사용할 수 있습니다.
이를 위해 입력 및 변환된 데이터가 나란히 표시됩니다. 또한 기술 통계를 계산하고 분류 모델을 생성하기 위한 훈련 셋으로 출력 데이터의 적합성을 분석할 수 있습니다. 해석을 돕기 위해 다양한 그래픽 및 숫자 표현이 표시됩니다.
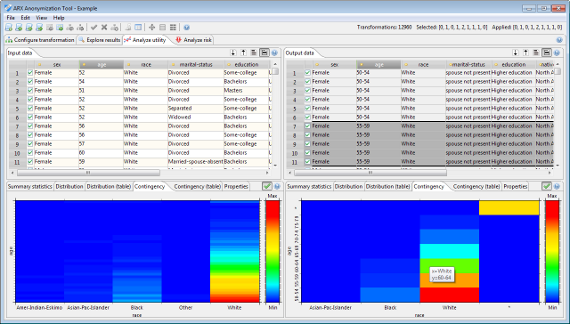
유틸리티 분석 관점은 출력 데이터 세트에 로컬 변환을 적용하는 데 사용할 수 있는 보기도 제공합니다.
- Analyzing data utility -
예상되는 사용 시나리오에 대한 출력 데이터의 품질과 유용성을 분석하는 데 사용할 수 있습니다.
이를 위해 변환된 데이터 셋을 원본 입력 데이터 셋과 비교할 수 있습니다. 상단에서 역역 (1)의 원본 데이터와 현재 선택된 영역 (2)의 변환 결과를 표시합니다. 두 테이블 모두 수평 또는 수직 스크롤 막대를 사용하여 탐색할 때 동기화됩니다. 영역 (3)과 (4)에서는 현재 선택된 속성에 대한 통계 정보를 비교할 수 있습니다.
보기에는 입력 및 출력 데이터 세트에 대한 일변량 및 이변량 통계 및 기본 속성의 결과가 추가로 표시됩니다. 또한, 동등한 클래스 및 억제된 레코드의 분포에 대한 통계에 대한 액세스를 제공합니다. 마지막으로 분류 모델을 구축하기 위한 훈련 세트로 출력 데이터의 적합성을 분석할 수 있습니다.
- Comparing input and output data -
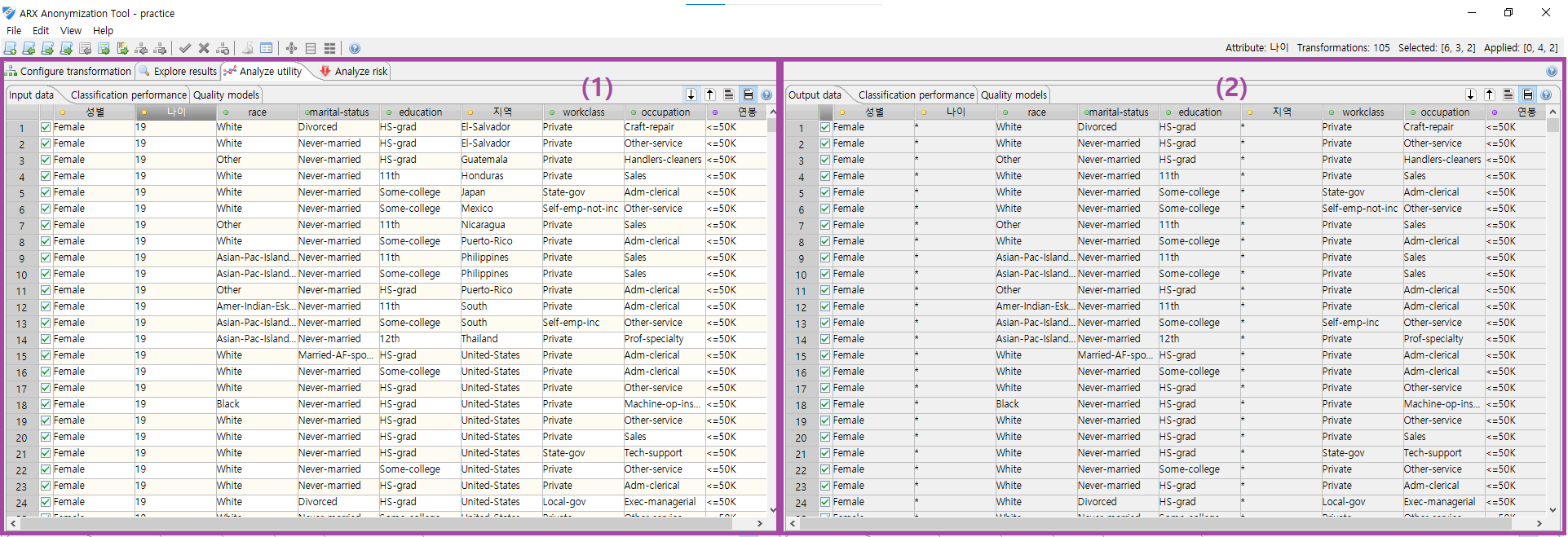
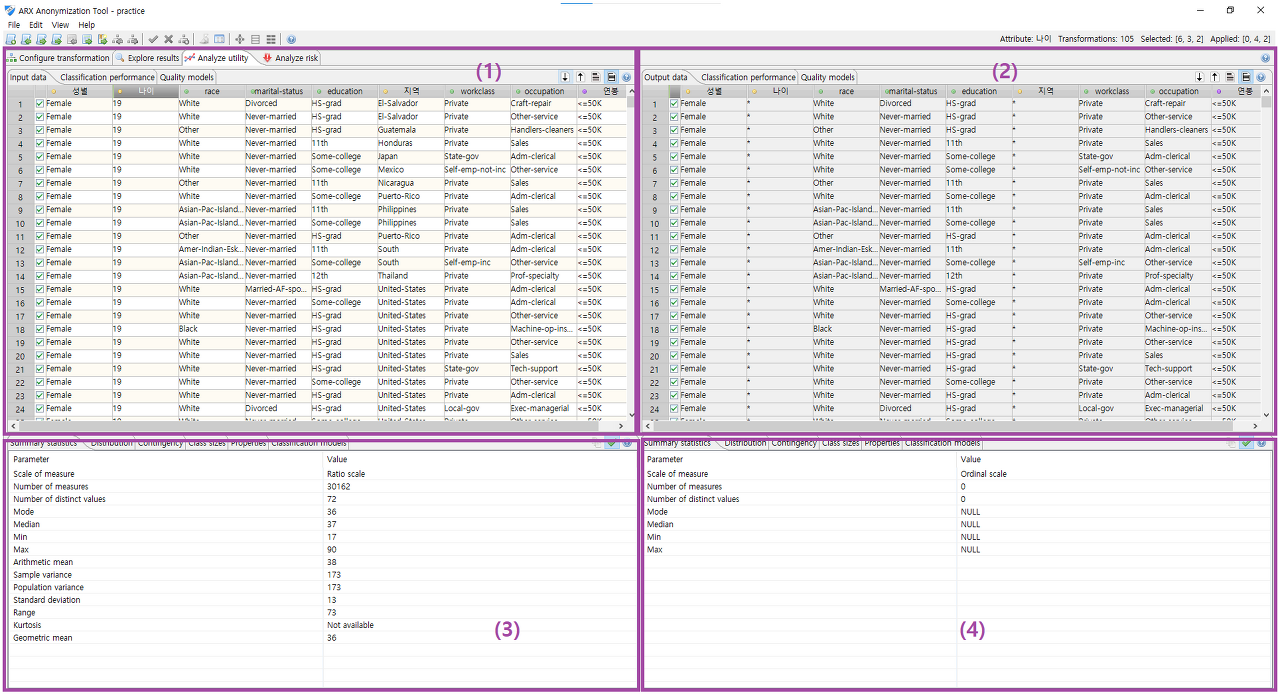
이 섹션에서는 변환된 데이터 셋을 원래 입력 데이터 셋과 비교할 수 있습니다. 두 테이블의 가로 및 세로 스크롤 막대가 동기화됩니다. 확인란은 연구 샘플의 일부인 행을 나타냅니다. 출력 데이터 셋을 표시하는 테이블의 확인란은 익명화 프로세스가 수행될 때 선택된 샘플을 나타냅니다. 변경할 수 없습니다. 입력 데이터 셋을 표시하는 테이블의 확인란은 현재 연구 샘플을 나타내며 편집 가능합니다.
각 테이블은 보기의 오른쪽 상단 모서리에 있는 버튼을 통해 액세스할 수 있는 몇 가지 옵션을 제공합니다.
- 첫 번째 버튼 : 선택된 속성에 따라 데이터가 정렬됩니다.
- 두 번째 버튼 : 모든 유사 식별자에 따라 출력 데이터 세트를 정렬한 다음 등가 클래스를 강조 표시합니다.
- 세 번째 버튼 : 데이터 셋의 모든 레코드가 표시되는지 또는 연구 샘플의 일부인 레코드만 표시되는지 토글됩니다.
- Summary Statics -
맨 아래에 있는 첫 번째 탭은 현재 선택된 속성에 대한 요약 통계를 보여줍니다.
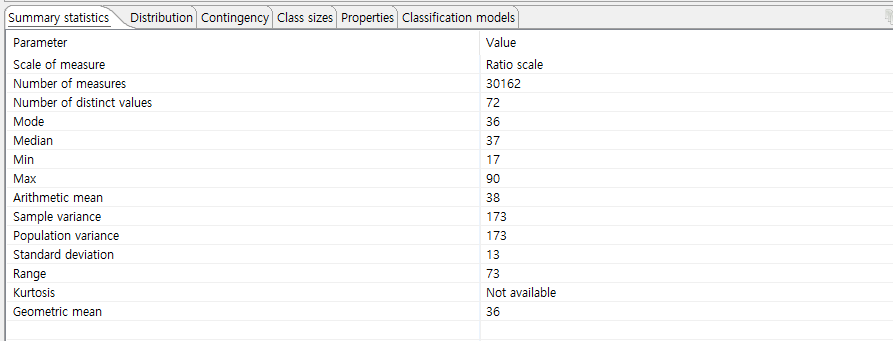
표시되는 매개변수는 변수의 척도에 따라 다릅니다. 명목 척도가 있는 경우 다음 매개변수가 제공됩니다.
- 방법.
서수 스케일이 있는 속성의 경우 다음 추가 매개변수가 표시됩니다.
- 중앙값, 최소값, 최대값.
간격 척도가 있는 속성의 경우 다음 추가 매개변수가 제공됩니다.
- 산술 평균, 표본 분산, 모집단 분산, 표준 편차, 범위, 첨도.
비율 척도가 있는 속성의 경우 다음 추가 매개변수가 표시됩니다.
- 기하학적 평균.
참고: 이러한 통계 매개변수는 누락된 데이터를 처리하는 방법인 목록별 삭제를 사용하여 계산 됩니다. 이 방법을 사용하면 단일 값이 누락된 경우 전체 레코드가 분석에서 제외됩니다. 이 동작은 프로젝트 설정에서 변경할 수 있습니다.
- Empirical distribution -
이 보기는 현재 선택된 속성 값의 빈도 분포를 시각화하는 히스토그램 또는 테이블을 보여줍니다.

- 통계에서 빈도 분포 : 표본에서 다양한 결과의 빈도를 표시하는 표.
테이블의 각 항목에는 특정 그룹 또는 간격 내에서 값이 발생하는 빈도 또는 개수가 포함되며, 이러한 방식으로 테이블은 샘플의 값 분포를 요약.
- 히스토그램 : 숫자 데이터 분포의 그래픽 표현. 연속 변수의 확률 분포 추정치. 히스토그램을 구성하기 위한 첫 번째 단계는 값 범위를 "bin"하는 것이며, 전체 값 범위를 일련의 간격으로 나눈 다음 각 간격에 속하는 값의 수를 계산.
- Contingency -
우연성을 뜻합니다.
이 보기는 선택한 두 속성의 우발적인 상황을 시각화하는 열 지도 또는 테이블을 보여줍니다.
우발성은 변수의 다변량 빈도 분포를 나타냅니다.

ARX는 원본 데이터 세트와 변환된 데이터 세트의 속성에 대해 비교 가능한 데이터 시각화를 제공하려고 합니다. 이를 위해 일반화 계층에서 추출한 속성의 데이터 유형 및 해당 값 간의 관계 정보를 사용합니다. 결과적으로 합리적인 데이터 유형과 계층을 지정하면 데이터 시각화의 품질과 유용성이 향상됩니다.
- Equivalence classes and records -
이 보기는 데이터셋의 레코드에 대한 정보를 요약합니다.
등가 클래스의 최소, 최대 및 평균 크기, 클래스 수, 억제 및 남아 있는 레코드 수를 보여줍니다.
"동등 클래스"는 지정된 준 식별 변수와 관련하여 구별할 수 없는 레코드 집합을 설명합니다. 때로는 등가 클래스를 "셀"이라고도 합니다.

출력 데이터 셋의 경우 모든 매개변수는 두 가지 변형으로 계산됩니다. 한 변형은 억제된 레코드를 고려하고 다른 변형은 억제된 레코드를 무시합니다.
- Properties of input data -
이 보기는 익명화에 사용되는 구성 및 입력 데이터 세트에 대한 기본 속성을 표시합니다. 이러한 속성에는 관련 변환 방법에 대한 데이터를 포함하여 데이터셋의 모든 속성에 대한 얕은 사양뿐 아니라 레코드 수와 억제 제한이 포함됩니다.
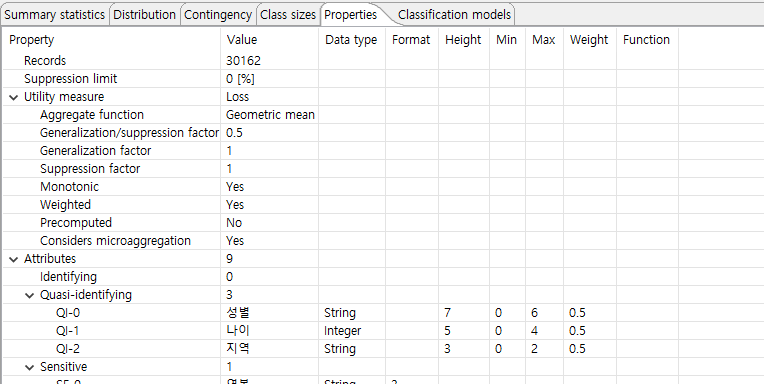
- Properties of output data -
이 보기에는 선택한 데이터 변환과 결과 출력 데이터 세트에 대한 기본 속성이 표시됩니다.
이러한 속성에는 지정된 유틸리티 측정 및 추가 설정(예: 속성 가중치)을 사용하여 계산된 점수, 억제된 레코드 수, 등가 클래스 수 및 억제된 레코드를 포함하는 클래스 수가 포함됩니다. 변환이 개인 정보 보호인 경우 모든 개인 정보 모델의 완전한 사양이 제공됩니다.
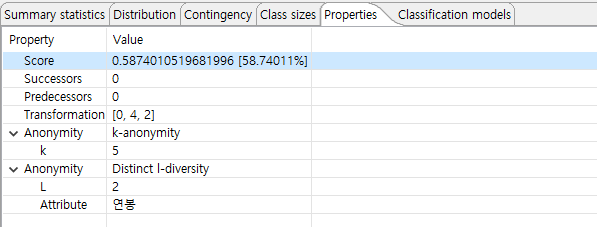
- Classification performance -
이 보기는 분류 모델 및 해당 매개변수를 구성하고 입력 및 익명화된 출력 데이터에 대해 훈련된 이러한 모델의 성능을 비교하는 데 사용할 수 있습니다. ARX는 모델 생성을 위한 훈련 세트로서의 적합성을 위해 출력 데이터를 최적화하기 위한 특정 품질 모델을 지원합니다.
왼쪽 하단에 표시되는 보기에서 기능 및 대상 변수를 선택하고 기능 스케일링 기능을 지정할 수 있습니다.
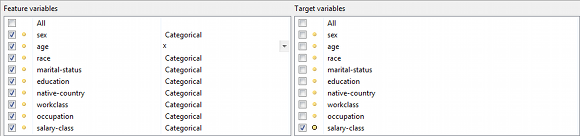
오른쪽 하단에 표시된 보기에서 다양한 유형의 분류 모델을 선택하고 구성할 수 있습니다.
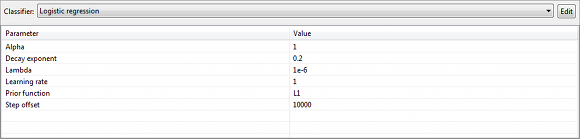
ARX는 현재 다음 유형의 분류 모델을 지원합니다.
- 로지스틱 회귀
- 랜덤 포레스트
- 나이브 베이즈
상단에서 탭으로 두 가지 다른 보기를 선택할 수 있습니다("개요" 및 "ROC 곡선"). 입력 및 출력 데이터의 경우 이러한 보기는 성능 분석의 다른 결과를 보여줍니다. 성능 측정은 일반적으로 수정되지 않은 입력 데이터에 대해 훈련된 간단한 ZeroR 분류기 및 입력 데이터에 대해 훈련된 선택된 유형의 모델의 성능과 관련하여 표현됩니다. 결과는 k-겹 교차 검증을 사용하여 얻습니다.
"개요" 보기의 테이블에는 (상대적) 분류 정확도와 민감도, 특이도 및 Brier 점수가 표시됩니다.

"ROC 곡선" 보기의 플롯 및 테이블은 대상 변수의 선택된 인스턴스에 대한 ROC 곡선 및 ROC 곡선 아래 면적(AUC)을 표시합니다.
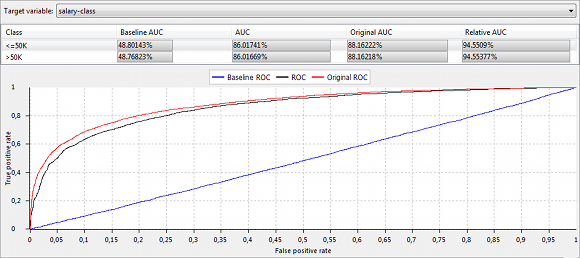
ARX는 다항 분류기에 대한 성능 측정을 계산하기 위해 일대일 접근 방식을 사용합니다.
- Data quality models -
이 섹션에서는 다양한 범용 모델을 사용하여 출력 데이터에 대해 얻은 데이터 품질 측정값을 표시합니다. 또한 속성의 데이터 유형과 누락된 값의 비율이 표시됩니다.
상단의 보기 : 속성 수준 품질, 즉 개별 준식별자와 관련된 품질 추정치.
하단의 보기 : 데이터 수준 품질, 즉 전체 준식별자 집합에 대한 품질 추정치.
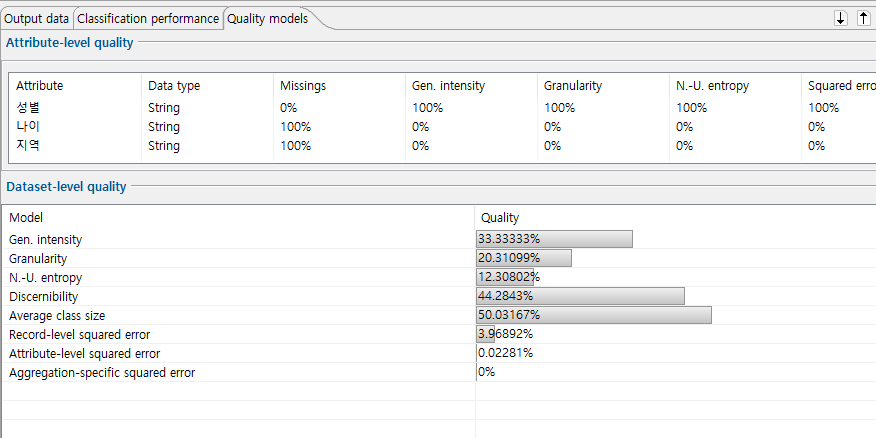
모든 속성 또는 데이터셋에 대해 모든 품질 측정이 반드시 지원되는 것은 아닙니다. 속성에 대해 품질 측정을 평가할 수 없는 경우 결과는 상단 테이블에 "N/A"로 표시됩니다. 결과적으로 동일한 모델을 사용하여 데이터 수준 품질을 계산할 때 이 속성도 무시되었습니다.
다음 속성 수준 품질 모델이 현재 구현되어 있습니다.
- 정밀도: 속성 값의 일반화 강도를 측정합니다.
- 세분성: 데이터의 세분성을 캡처합니다.
- 불균일 엔트로피: 속성 값 분포의 차이를 수량화합니다.
- 제곱 오류: 값을 숫자로 해석하고 구별할 수 없는 레코드 그룹의 제곱 오류 합계를 캡처합니다.
또한 다음 데이터세트 수준 품질 모델을 사용할 수 있습니다.
- Average class size : 구별할 수 없는 레코드 그룹의 평균 크기를 측정합니다.
- 식별성: 식별 할 수 없는 레코드 그룹의 크기를 측정하고 완전히 억제된 레코드에 대한 패널티를 도입합니다.
- 모호성: 레코드의 모호성을 캡처합니다.
- 레코드 수준 제곱 오류: 레코드를 벡터로 해석하고 구별할 수 없는 레코드 그룹의 제곱 오류 합계를 캡처합니다.
'IT 일기 (상반기) > 가명처리' 카테고리의 다른 글
| [ARX] ARX privacy model - Privacy model (0) | 2021.11.15 |
|---|---|
| [ARX] ARX 이해하기 - Risk analysis perspective (0) | 2021.11.12 |
| [ARX] ARX 이해하기 - Exploration perspective (0) | 2021.11.11 |
| [ARX] ARX 이해하기 - Configure perspective (0) | 2021.11.11 |
| [ARX] ARX 실습 - Example 파일 활용(연봉) (0) | 2021.11.10 |



