
겉바속촉
[ARX] 비식별화 본문
728x90
반응형
비식별화 개념
1. 정의
데이터 내에 개인 식별 정보가 있는 경우,
이의 일부 또는 정부를 삭제 또는 일부를 속성정보로 대체 처리
다른 정보와 결합하여도 특정 개인을 식별하기 어렵도록 조치하는 것
비식별화 방법
1. 일반적 기법 : 개인 식별요소 삭제 방법
- 가명처리
전 : 보라돌이, 32세, 서울 거주, 햇님대 재학
후 : 이순신, 30대, 서울 거주, 달님대 재학
세부기술 -> 휴리스틱 가명화, 암호화, 교환 방법 - 총계처리
전 : 보라돌이 180cm, 뚜비 170cm, 나나 160cm, 뽀 150cm
후 : 텔레토비과 키 합 : 660cm, 평균키 165cm
세부기술 -> 총계처리, 부분총계, 라운딩, 재배열 - 데이터 삭제
전 : 주민번호 981209-1234567
후 : 98년대 생, 남자
세부기술 -> 식별자 삭제, 식별자 부분 삭제, 레코드 삭제, 식별요소 전부삭제 - 데이터 범주화
전 : 보라돌이, 43세
후 : 보라씨, 40 ~ 50세
세부기술 -> 감추기, 랜덤 라운딩, 범위 방법, 제어 라운딩 - 데이터 마스킹
전 : 보라돌이, 32세, 서울 거주, 햇님대 재학
후 : 보라**, 32세, 서울 거주, **대학 재학
세부기술 -> 임의 잡음 추가, 공백과 대체
2. 기법과 의미
| 기법 | 의미 | 적용 예시 |
| k-익명성 | - 특정인을 추론할 수 있는지 여부 검토 - 일정 확률 수준 이상 비식별이 되도록 함 |
동일한 값을 가진 레코드를 k개 이상으로 함. 이 경우 특정 개인 식별 확률 : 1/k |
| l-다양성 | - 특정인 추론이 안됨 - 민감 정보의 다양성을 높여 추론 가능성을 낮추는 기법 |
각 레코드는 최소 1개 이상의 다양성을 가지도록 하여 동질성 또는 배경지식 등에 의한 추론 방지 |
| t-근접성 | - l 다양성뿐만 아니라, 민감정보의 분포를 낮추어 추론 가능성 낮추는 기법 | 전체 데이터 집합의 정보 분포와 특정 정보의 분포 차이를 t이하로 하여 추론 방지 |
비식별화에서 가장 기본적인 기법 : k-익명성
민감정보가 포함되는 경우 l-다양성, t-근접성의 방법론도 고려해야 함.
** t-근접성 **
k-익명성, l-다양성을 만족하더라도 해당 조합의 민감정보 분포가 다른 조합의 분포와 차이가 크면 분포의 차이로 인해 민감정보가 유출되는 것이므로 모든 가능한 조합 n개에 대해 구한 n(n-1)/2 개의 거리가 임계값 t 보다 작게 만들자는 개념
Disease는 민감정보이지만 거리를 계산할 수 없는 형태인 경우,
t 근접성은 거리를 계산하여야 하는데 문제는 명목척도이기 때문에 거리 계산이 불가능한 것
이에 대한 해결방법으로 병에 대한 위계도(Hierarchy plot)를 이용하는 방법을 고려할 수 있습니다.
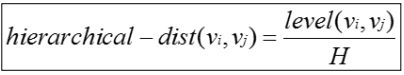

비식별화의 어려움
보유 정보가 다음과 같은 경우에 해당한다면 k-익명성 충족이 어려울 수 있습니다.
- 준식별자의 수가 너무 많은 경우
분석에 불필요한 준식별자는 삭제
준식별자가 증가하면 Population Uniqueness Issue가 발생한다.
**준식별자 의미**
연령, 성별, 거주 지역, 국적 등과 같이 해당 데이터만으로는 직접적으로 특정 개인을 식별할 수는 없지만, 다른 정보와 결합하여 개인을 식별할 수 있는 데이터 - 특정 준식별자 조합에 해당하는 Record 수가 k 미만인 경우(1명만 제주도 거주하는 경우 등)
빈도분석을 통해 해당 관측값을 찾고 분석에 크게 문제가 없다면 이를 삭제. - 심한 비대칭분포
연속변수의 경우는 로그변환 등을 통해 균등분포 혹은 정규분포 모양을 만드는 것이 좋음.
명목변수인 경우, 빈도가 작은 Cell을 Pooling하여 일정 수 이상의 빈도를 확보하는 것이 좋음.
**연속변수**
양의 크기를 나타내기 위하여 수량으로 표시되는 변수로 주어진 범위 내에서 어떤 값도 가질 수 있는 변수. 소수점으로 표시될 수 있는 변수로 길이, 무게 등
**명목변수**
변수의 값이 측정 대상을 특정한 범주 안에 들어가게 하지만 해당 범주간에 순위가 미존재. 특성을 이름으로 구별하는 변수 - 민감 정보가 포함되어 있는 경우
l-다양성이나 t-근접성을 만족해야 하는데 보유 정보가 다음과 같은 경우에 해당한다면
l-다양성이나 t-근접성 충족이 어려울 수 있으므로 적절한 조치를 취해야 함.
- 준식별자와 민감정보의 상관 관계가 큰 경우 : 관측치의 개수를 늘려 같은 준식별자 수준에서 다양성을 만족할 수 있도록 해야 한다.
- 민감정보가 여러 개 존재하는 경우 : 민감정보는 각각에 대해 , l-다양성이나 t-근접성 기준을 설정하므로 여러 개를 동시에 설정할 경우, 특정 정보 하나가 기준을 만족하지 않아 모두 만족하지 않는 것처럼 변환될 수 있다. 이 경우, 그 특정 정보를 삭제할 수 있다면 좋은 변환을 할 수 있다.
728x90
반응형
'IT 일기 (상반기) > 가명처리' 카테고리의 다른 글
| [ARX] ARX 실습2 - 나이 Interval, 주소 변환 (0) | 2021.11.10 |
|---|---|
| [ARX] ARX 실습1 - 성별 마스킹 (0) | 2021.11.10 |
| [ARX] ARX 설치 및 실행 (0) | 2021.11.09 |
| [개인정보보호법] 데이터 거버넌스 프레임워크 컴포넌트 (0) | 2021.07.29 |
| [개인정보보호법] 데이터 거버넌스 프레임워크 (0) | 2021.07.29 |
'IT 일기 (상반기)/가명처리' Related Articles
more



